"Our problem is that we never do the same thing again. We
get a lot of experience on our first simple system, and
when it comes to doing the same thing again with better
designed hardware, with all the tools we know we need, we
try and produce something which is ten times more
complicated and fall into exactly the same trap. We do
not stabilize on something nice and simple and say "letĺs
do it again, but do it very well this time."
David Howarth [H072]
The members of this second sub-group had a fairly clear idea of the sort of functions that a modern virtual memory operating system should provide, as well as the level of performance it should achieve based on almost ten years experience with these sorts of systems. This experience had been gained primarily in the design, development, use and modification of the Edinburgh Multi-Access System, but was tempered also by the experience of others aquired both from the open literature and more directly in face to face discussion. Even with this experience, or perhaps because of it, the sub-group felt that the evaluation should consist of a study of the effect that the architecture had on a real operating system and not a study of the architecture in isolation. Three operating systems were identified as candidates for this evaluation.
The second candidate appeared initially most attractive. Versions of MUSS existed while a re-implementation of EMAS was merely an idea. It appeared to be well structured and efficient, and the use of MUSS seemed also to form a basis for collaborative research involving both the Edinburgh and the Manchester departments of computer science, but after much effort both in Edinburgh and Manchester it too was rejected as a candidate. There were two reasons for its rejection. The first was timing. At the time the Edinburgh sub-group needed it, the 2900 version of MUSS was still being implemented. The second was that the Edinburgh group felt uncomfortable with the software technology used in constructing MUSS, and with the impact this had on our ability to either modify or extend it.
Thus with some sadness at the failure of the MUSS approach, the task of re-implementing EMAS for the ICL 2900 was started. At this point the university computing centre expressed an interest in seeing EMAS re-implemented for the ICL 2900 as an alternative to the manufacturerĺs operating system. Without making any commitment to use a finished product, they were willing to commit staff to the project and a full scale re-implementation excercise was launched which had as its goal the development of a full production system and not merely an architectural evaluation.
We felt that it was necessary to alter the structure of the existing 4/75 EMAS system for three reasons:-
The project has had ten members. A six man core consisting of four full time workers and two part time workers has implemented most of the system. This group have been augmented by a second group of about four, who were available to make specific contributions in an area of expertise (for example device handlers). The contribution of this second group has been very limited in time, to the extent that there have never been more than one or two of them active at the same time.
Why has it been possible to handle a project of this scale with such a small team and in such a relatively short period of time? We have been able to identify three factors. The first was that all the tools required by the project already existed, were effective, and could be trusted. The second and perhaps the most important was that all the individuals involved possessed a consistent and complete model of that which they were implementing. The third was the quality of the staff involved, who have on average considerably more than ten years system construction experience and a host of large projects to their credit.
It is incredible that academics as well as manufacturers continue to implement production operating systems in new and often barely implemented languages. The implementation of MULTICS in PL/1, and 4/75 EMAS in IMP are two historical examples. The implementation of the SUE operating systems in the SUE language, and ICLĺs SUPERVISOR B in S3 are two more recent examples. Having ourselves once faced the problems of writing an operating system on the shifting sands of an initial language implementation, we did not wish to do so again, and believe it should be avoided at all costs. We have also observed that a major problem in operating systems implementation, even with relatively small teams, is that team members do not share a common model of the system, individual parts of which they are implementing. One of the ways that this problem may be overcome is by first building prototype model systems, which can then be developed into products through re-implementation.
The system is being implemented in the same dialect of the Edinburgh Implementation Language (IMP) [ST74] as was the initial EMAS system. This is being done despite the existence of more modern and consistent dialects of IMP [RO77] and the existence of languages such as CONCURRENT PASCAL [HA75] and MODULA [WI76]. There are three reasons for this choice. Firstly, we wish to transport some programs from the existing 4/75 system. Secondly, we understood the language, both how to use it and how to compile it. Thirdly and perhaps most importantly it already existed, not only the language and a robust compiler, but source code formatters, trace packages and post-mortem diagnostic procedures as well.
It is perhaps best to consider diagnostics in two classes, those that are produced dynamically while the system is running and those that are produced statically by a system post-mortem procedure after a system failure.
In both cases language based diagnostics can be produced. Language based diagnostics and checks have always existed in IMP. For example code can be inserted by the compiler to check on the validity of array indices or to check that variables have been written to before they are read from, for casting run time error messages in source language terms and for outputing the names and values of all variables on the dynamic stack either at the time of error or on demand. For reasons that we do not understand, it was believed, at the time EMAS was originally implemented, that such checks and output would be either impossible or too expensive in an operating system. This is not the case, and therefore these facilities have been included in the re-implemented system, though of course they can be disabled by re-compilation in production systems to save time and space.
In addition to language based diagnostics, the running system can also produce traces. The most fundamental type of trace is a module trace. Module tracing is extremely easy in any message-based system such as EMAS. All messages go through a single central mechanism, and therefore the cost in code, if not in time, of tracing messages is small. As the flow of messages through the system is high, a certain selectivity is needed. Therefore one is able to nominate the subset of messages to be traced by specifying either their source or destination addresses. Module tracing can be enabled and disabled either from the operatorĺs console or by any supervisory module or process. Nearly all of this was in the original version of EMAS and proved useful. In addition any module can output its own trace information using standard language I/O procedures. In this way other forms of trace are produced, such as page fault traces or channel use traces.
During early system development we were, in the case of a system failure, able to produce a small post-mortem analysis without having to resort to a dump. This was achieved by using the restart facility provided by the hardware, to enter a post-mortem diagnostic procedure. Using activation records, and information provided when the system was built, this procedure was able to provide a limited printout containing language based diagnostics, register values, re-assembled machine orders from around the point of failure and annotated tables in a format which matched their structure rather than the width of the print line. In those rare instances when this was not enough, or the post-mortem procedure failed, we had to resort to the tedium of a full dump. We had the experience of de-bugging the first EMAS system using uninterpreted dumps as the main means of fault analysis. It was an unnecessarily slow and tedious process.
As the system became more robust it was felt that a two stage post-mortem procedure was more appropriate, both because there was more information needed which was increasing the size of the resident prccedure, but also because greater selectivity was needed in chosing what to analyse. The first stage which is entered via the restart facility dumps the store to tape from which it can be analysed interactively at a later stage. While this is more appropriate in a production system, we would continue to recomend the inclusion of an immediate post-mortem analysis package to suport the early stages of system development.
As the development of the system progressed the emphasis moved from that of error detection and correction to that of performance measurement and improvement. There were three tools available to the project for performance measurement and one that we wished we had. The three tools were a simple module execution profiling facility, an event tracing facility and a remote terminal emulator [AD77] built into the communications network. The tool we did not posses was a language based execution profiling facility.
The module execution profile is generated in the resident supervisor and output on demand. The module dispatcher maintains three counts for each module. These are a count of the number of times the module is entered, a count of the total number of instructions executed in the module and a count of the total amount of time spent in the module. This profile is useful for determining where time is being spent and possibly being wasted in the system.
The event tracing facility produces an event trace in the same format as that produced by 4/75 EMAS, so that the same utility programs can be used to manipulate it and to build a detailed analysis of resource usage and contention.
The remote terminal emulator is perhaps the most important performance measurement tool we posses both because it allows us to measure the performance of the system as seen by a user at a terminal, and because it provides us with repeatable loads. As the remote terminal emulator sits on the network, an emulated terminal and emulated user are indistinguishable from a real terminal and real user. In addition, as performance data is gathered by the emulator, its use introduces no measurement overheads into the system. The availability of the remote terminal emulator has made it possible to study the effects of a software change quantitatively rather than qualitatively.
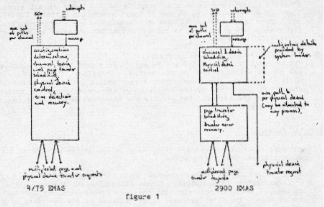
In the 4/75 system, a device handler would on initialization determine the configuration of devices for which it was responsible. It would build a data structure, descriptive of this configuration, for its own use in device and channel scheduling. In the re-implemented system both the configuration function and the channel scheduling function have been factored out of the device handler, leaving it to perform the conversion of multiple logical I/O commands for each logical device into sequential physical device command programs for each real device. (In the case of ICL 2900 drums, the hardware accepts logical I/O commands directly, and therefore no translation is required.) Figure 1 is a schematic of the old and the new structures.
In EMAS, unike other fully paged systems, page replacement is not a global function performed over all available page frames in the system, but a function performed separately, for each virtual process in the multi-programming set, over a set of page frames allocated to each virtual process upon its entry to the multi-programming set. This functional organization is not manifest in the structure of the 4/75 system, where page replacement and other virtual memory control functions are performed by modules in the resident supervisor. In the re-implemented system, there is instead a module, called a local controller associated with each virtual process in the system. Each local controller is only active while the virtual process with which it is associated is in the multi-programming set and is paged out when the virtual process is removed from the multi-programming set. Figure 2 is a schematic of the old and the new structures.
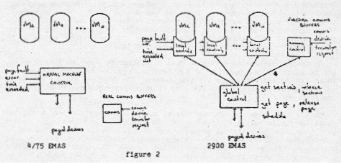
In the new structure, each module is also serially re-entrant, though the code may be shared by a number of local controllers running in parallel. Each local controller is entered via a trap from the associated virtual process (a page fault is a synchronous event and not an interrupt) or upon a return from a call made by a local controller upon the global controller.
The global controller is effectively a monitor, or series of monitors, that handles page movement between the various levels of the storage hierarchy, and the allocation of resources to a local controller for a period of process time. The global controller does not enrorce this allocation, and depends upon the honesty of the local controllers in staying within their allocations. Local controllers must therefore be trusted programs and cannot be provided by a user at will.
Two approaches were used in the 4/75 EMAS system. In the first, DIRECTOR copied data between a userĺs virtual memory and dedicated buffers in locked down real store. The transfer was performed in response to commands issued by the userĺs process and external I/O activity. This approach carried with it a high overhead, as a number of DIRECTOR pages were required to perform this operation, and if the data transfer was larger than the buffer size the process would be paged in and out of store merely to refill the buffer rather than to procede. This had the effect non only of incurring paging activity, but also of altering the identity of the userĺs working set.
This approach was modified with the advent of network operation, so that DIRECTOR transfered data between virtual memory and inter-process messages, which are sent to or received from the communications front-end processor. As these messages are small all interactive traffic has to be fragmented into 18 character packets. As only limited number of packets (10) may be sent ahead without acknowledgement, similar unneccessary paging activity is introduced for transfers of over 180 characters length.
In the re-implemented system we make an attempt to overcome this problem, and to integrate the handling of RJE traffic from the SPOOLing manager and inter-machine traffic within the same scheme. The SPOOLing manager currently multiplexes large blocks into the flow of inter-process messages to and from the front-end.
In the new scheme a special virtual memory is maintained by a special local controller called the "communications controller". This virtual memory is not accessed by a virtual processor, as is a userĺs virtual memory, but by communications front-end processors and spooled peripherals to perform data transfers. The virtual memory controlled by the communications controller contains files which in turn contain input or output buffers. Pages of these files are transfered into primary memory by the communications controller in response to peripheral transfer requests, in the same way that a local controller transfers a page to primary memory upon the ocourance of a page fault. A page brought to primary memory by the communications controller needs only remain in primary memory until the transfer which operates as a burst completes, though there Is a delay involved before the communications controller releases the page. This allows a page to be reclaimed while still in primary memory, so that either the next burst transfer can procede directly or a process sharing the file can claim the page before it is removed frcm memory.
In the case of interactive traffic these communications buffer files (one for input and one for output) will also be connected into a userĺs virtual memory. The user will read input from the input buffer file and will write output to the output buffer file. Synchronization being performed by director calls which in turn cause inter-process messages to be sent to a front end processor via the communication controller. In the case of spooled I/O, the files to be input ot output will themeselves serve as communications buffer files. They will not be connected into another virtual memory at the same time.
The advantages of this approach are that no pages need to be permanently tied down in main store and that the unit of transfer between the front-end and the main-frame can be appropriate to that logical interface, while the unit of transfer handled by the system remains a page. As all page sharing is handled by the global controller, a userĺs local controller will normally request the relevant input page before the communications controller releases it. In the case of output, only one buffer page is paged in if more than one burst transfer to the front-end Is required and not the user and director processes as has previously been the case
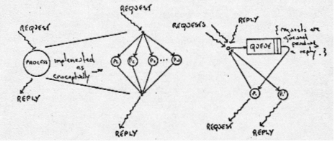
In the 4/75 system, a process is invoked by a message addressed to it. If a process can receive a number of different messages, the body of the process will take the form of a case statement (Figure 3). As long as the process does not itself need to interact with another process this poses no problems. If it does, it will receive a reply multiplexed into the incoming message stream. As a system-process must relinquish control before another system process can be invoked, a single activity punctuated by a request on another process and the reception of a reply must be implemented by two arms of the case statement. If the process requires to maintain the context of the first arm while awaiting the reply, it must either queue all other messages received before the reply, or possess a means of saving multiple contexts. Neither approach is particularly satisfactory. By giving each process three addresses, we allow it to receive synchronous requests at one address, replies at a second and asynchronous events at a third. The system also provides a means of inhibiting and enabling a message stream by destination address. Using this facility a process may inhibit the arrival of requests while awaiting a reply, thereby using a simple global mechanism to eliminate the need for message queueing within the process or the handling of multiple contexts. Figure 4 is a schematic of the new structure.
